하위 태스크 1
CTE 기본 예제 실행
08-2.sql의 기본 CTE 예제를 실행하고, 구조를 주석으로 분석
다음은 customer 테이블에서 customer_id 열의 값이 10 이상 100 미만인 행을 선택해 논리적 테이블을 생성한다. 그리고 해당 테이블의 모든 데이터를 조회한다.
WITH
cte_customer (customer_id, first_name, email) AS (
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 10
AND customer_id < 100
)
SELECT
*
FROM
cte_customer;CTE 대신 인라인 뷰를 사용해서 같은 결과를 조회하는 SQL 문은 다음과 같다.
SELECT
*
FROM
(
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 10
AND customer_id < 100
) AS inline_customer;CTE 사용 시 논리적 테이블을 구성하는 구간과 SELECT 문을 사용하는 구간이 분리되어 가독성이 좋지만, 인라인 뷰는 여러 SELECT 문이 중첩되어 있어서 더 복잡해질 경우 가독성을 보장할 수 없다.
하위 태스크 2
집합 연산 연습
UNION/INTERSECT/EXCEPT 예제를 실행하고 결과 차이 이해
UNION ALL 결합 예제:
WITH
cte_customer (customer_id, first_name, email) AS (
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 10
AND customer_id <= 15
UNION ALL
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 25
AND customer_id <= 30
)
SELECT
*
FROM
cte_customer;6번째 행과 7번째 행을 경계로 두 SELECT 문의 조회 결과가 결합되었다.
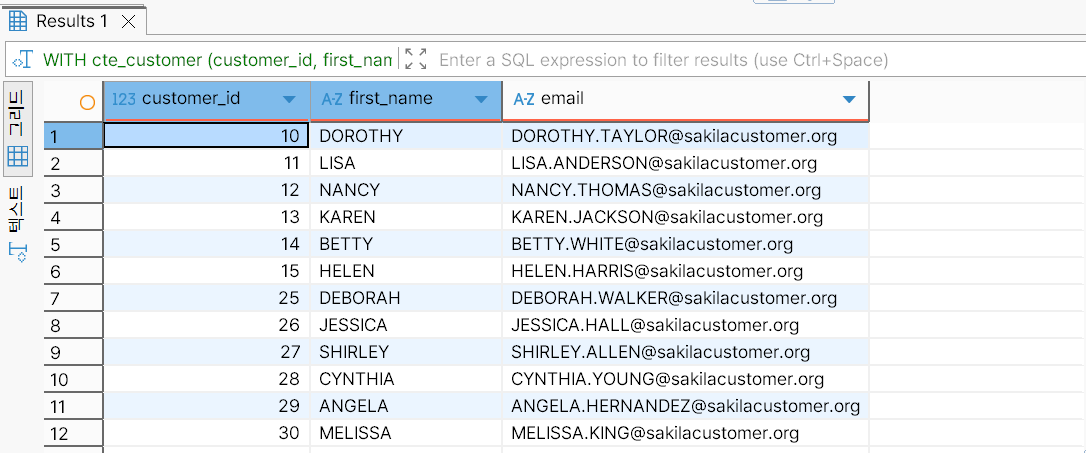
INTERSECT 결합 예제:
WITH
cte_customer (customer_id, first_name, email) AS (
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 10
AND customer_id <= 15
INTERSECT
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 12
AND customer_id <= 20
)
SELECT
*
FROM
cte_customer;첫 번째 SELECT 문은 customer_id가 10 이상 15 이하인 고객을 조회하고, 두 번째 SELECT 문은 customer_id가 12 이상 20 이하인 고객을 조회한다. INTERSECT 연산자는 이들의 중복값을 걸러 반환하기 때문에 두 CTE를 결합한 결과는 customer_id가 12 이상 15 이하인 고객을 선택한 논리적 테이블이다.
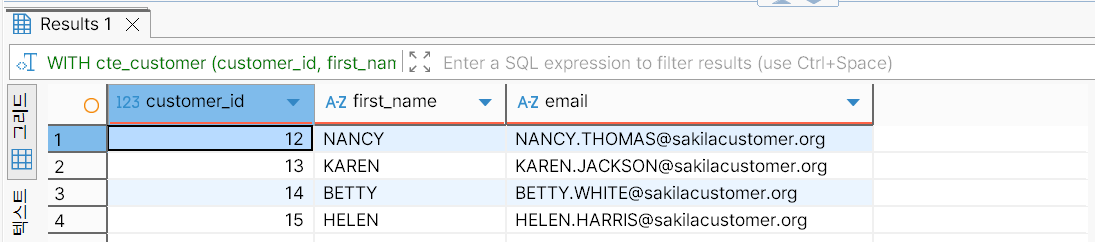
EXCEPT 결합 예제:
WITH
cte_customer (customer_id, first_name, email) AS (
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 10
AND customer_id <= 15
EXCEPT
SELECT
customer_id,
first_name,
email
FROM
customer
WHERE
customer_id >= 12
AND customer_id <= 20
)
SELECT
*
FROM
cte_customer;EXCEPT 연산자는 첫 번째 결과 집합에서 두 번째 결과 집합에 포함된 행을 제외한다. 첫 번째 SELECT 문과 두 번째 SELECT 문의 중복은 customer_id가 12 이상 15 이하인 행에서 발생한다. 따라서 최종적인 조회 결과는 customer_id가 10 이상 11 이하인 행을 포함한다.

하위 태스크 3
재귀 CTE 실습
피보나치 수열 생성 예제를 실행하고 anchor/recursive 부분 분석
CTE 정의부에 앵커 멤버와 재귀 멤버의 위치를 주석으로 표시했다.
WITH RECURSIVE
fibonacci_number (n, fibonacci_n, next_fibonacci_n) AS (
SELECT -- 앵커 멤버
1,
0,
1
UNION ALL
SELECT -- 재귀 멤버
n + 1,
next_fibonacci_n,
fibonacci_n + next_fibonacci_n
FROM
fibonacci_number
WHERE
n < 20
)
SELECT
*
FROM
fibonacci_number;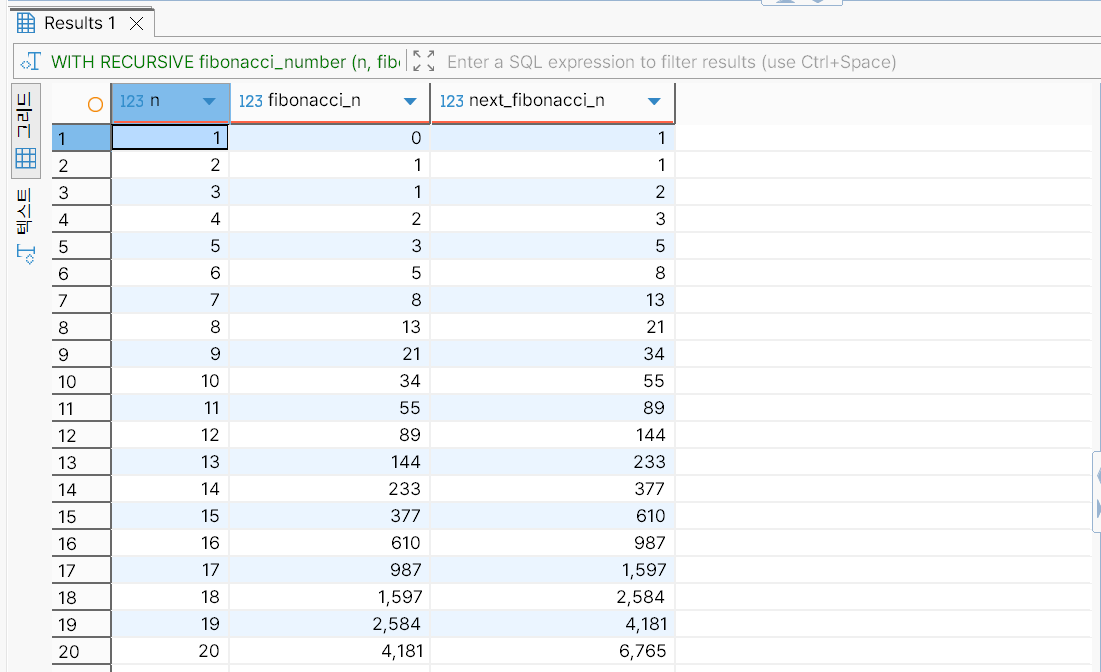
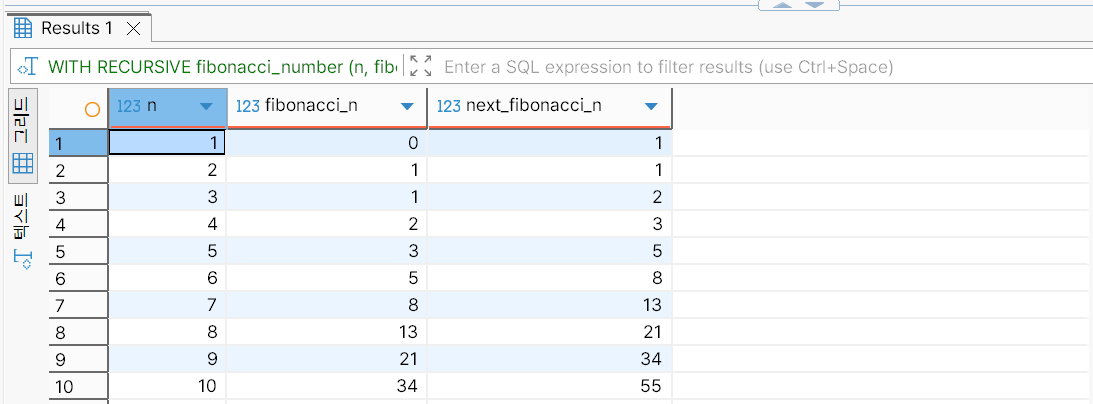
WHERE 절의 n < 20 조건을 n < 10으로 바꾼 뒤 실행한 결과는 다음과 같다. 반복이 10회 감소함에 따라 행의 개수도 10개 감소했다.
하위 태스크 4
재귀 CTE 응용 쿼리 작성
1~N 합계 또는 간단 계층 구조를 재귀 CTE 로 표현
1부터 10까지의 합을 구하는 재귀 CTE를 사용해 작성한 SQL 문은 다음과 같다.
WITH RECURSIVE
sum_to (n, result) AS (
SELECT
0,
0
UNION ALL
SELECT
n + 1,
result + n + 1
FROM
sum_to
WHERE
n < 10
)
SELECT
*
FROM
sum_to;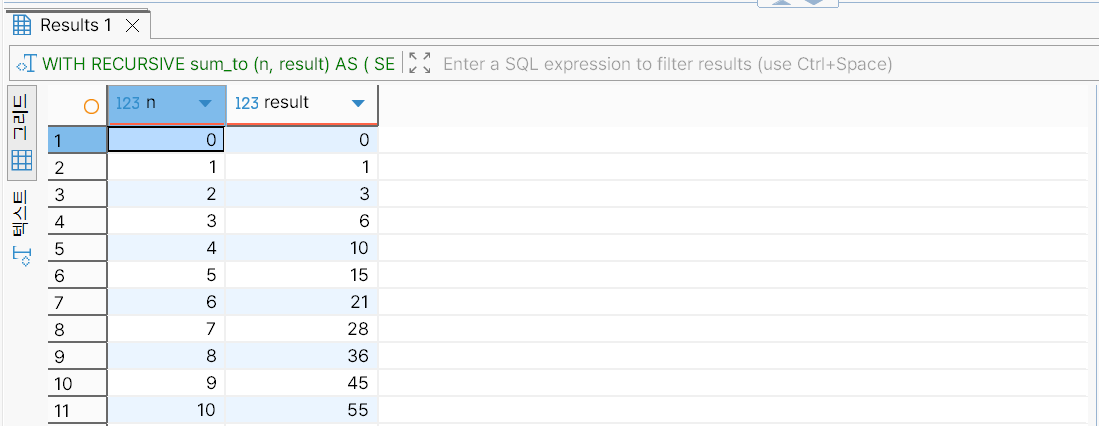
하위 태스크 5
us_stock스키마 구축
08-3.sql로 us_stock DB 와 테이블 생성, 인덱스 확인
us_stock 데이터베이스가 생성되었는지 확인한다.
SHOW DATABASES;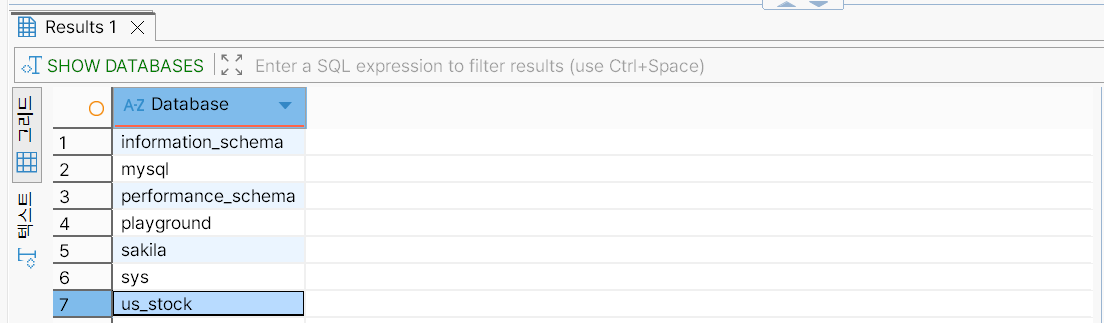
nasdaq_company 테이블과 stock 테이블이 생성되었는지 확인한다.
USE us_stock;
SHOW TABLES;
stock 테이블에 인덱스가 생성되었는지 확인한다.
SHOW INDEX FROM stock;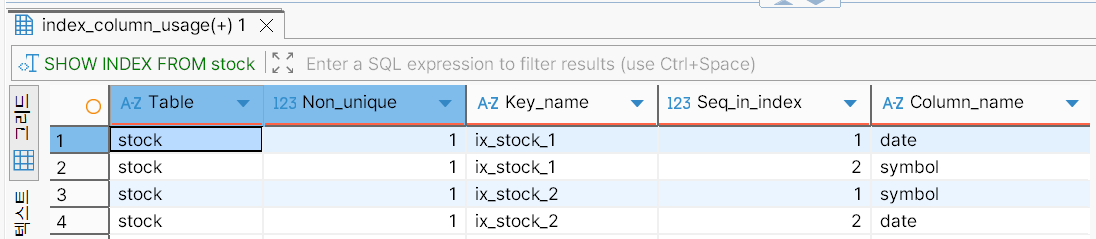
하위 태스크 6
기본 주식 데이터 삽입/조회
nasdaq_company샘플 데이터 삽입 및 조회
일련의 INSERT 문 실행 후 nasdaq_company 테이블에 데이터가 삽입되었는지 확인한다.
SELECT * FROM nasdaq_company;
하위 태스크 7 ~ 8
윈도우 함수 분석 쿼리 작성
stock 테이블에 대한 순위/누적합/이동평균 쿼리 작성
CTE+윈도우 결합 리포트
CTE 와 윈도우 함수를 결합한 분석 리포트를 설계
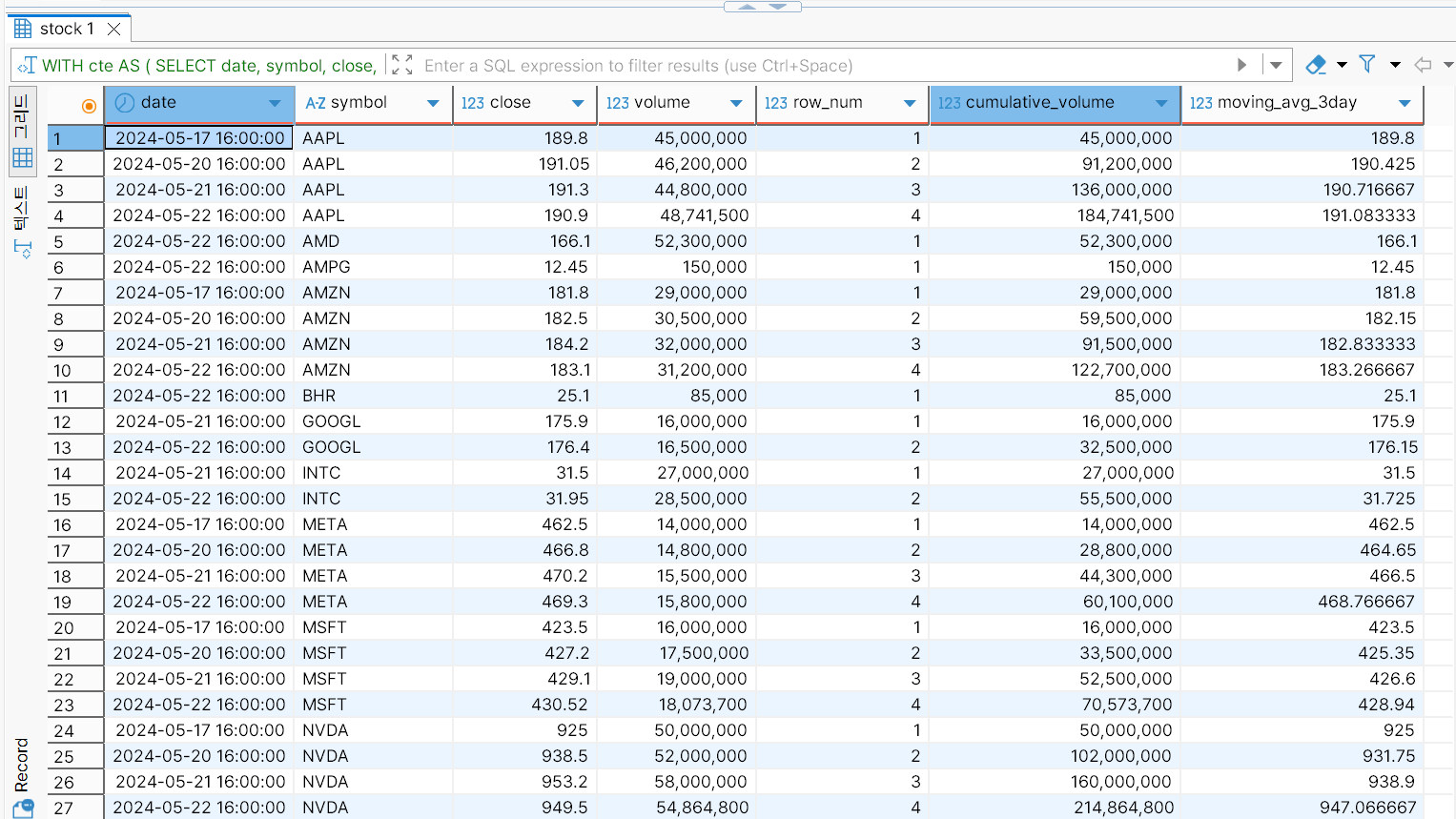
다음은 stock 테이블에 대한 분석 쿼리를 작성한 것이다. CTE와 윈도우 함수(ROW_NUMBER, SUM, AVG 등)를 활용하였다.
row_num열: 종목별 날짜 순서대로 정렬한 뒤 순번을 부여한다.cumulative_volume열: 종목별 날짜 순서대로 정렬한 뒤 거래량의 누적 합계를 계산한다.moving_avg_3day열: 종목별 날짜 순서대로 정렬한 뒤 3일 이동 평균을 계산한다.
WITH cte AS (
SELECT
date,
symbol,
close,
volume,
ROW_NUMBER() OVER (PARTITION BY symbol ORDER BY date) AS row_num,
SUM(volume) OVER (PARTITION BY symbol ORDER BY date) AS cumulative_volume,
AVG(close) OVER (
PARTITION BY symbol
ORDER BY date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg_3day
FROM stock
)
SELECT * FROM cte
ORDER BY symbol, date;